
High Availability (HA)
The two main components of any HA deployment are Failover for fault tolerance and Load balancing for maintaining an acceptable level of performance. NXLog integrates with third-party load balancing solutions and ships with built-in failover capabilities.
Failover
Configuring a cluster of redundant, multiple systems able to provide identical functionality is the first prerequisite for implementing failover. Such a cluster is also known as an active-passive cluster. See NXLog Failover Mode for a detailed guide on configuring NXLog externally managed active-passive clusters.
Creating an NXLog failover cluster for centralized log collection
The following diagram illustrates how the externally managed failover functionality inherent in each of the NXLog v5 agents belonging to the Log Sources group can be individually configured to define not only the nodes that will comprise the NXLog Relay Cluster, but also which node will be active.
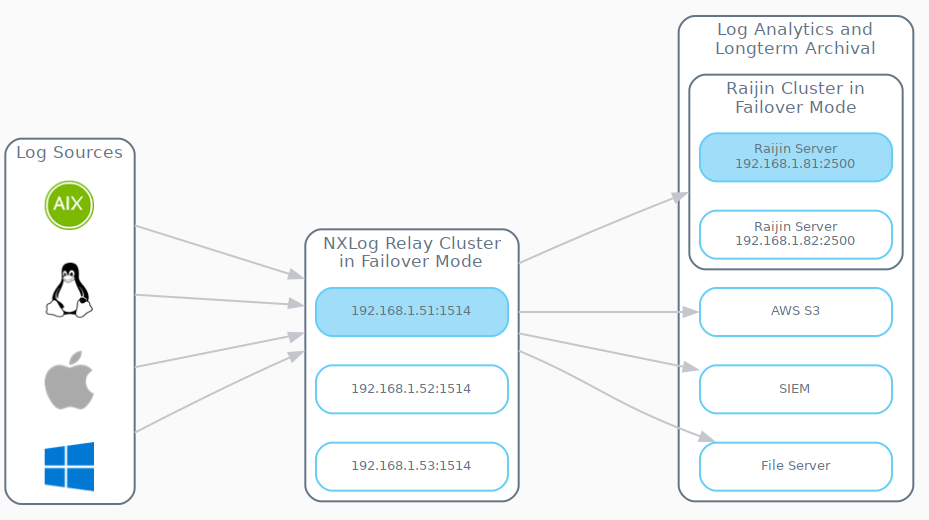
The architecture exhibited above includes a Raijin Server Cluster comprised of two nodes. It too will operate in the same manner as the NXLog Relay Cluster, failing over to the next passive node if the active node fails.
To summarize, the failover for the NXLog Relay Cluster is configured in the om_tcp instance of each agent in the Log Sources group. The failover for the Raijin Server Cluster is configured in the om_raijin output instance of each agent in the NXLog Relay Cluster.
|
Only NXLog v5 agents can provide external failover, thus the architecture presented here works only with agent-based log collection, not with agentless log collection. |
Examples of failover implementations
The following sections cover the configurations needed to manage a cluster of NXLog relay nodes in active-passive mode. It is important to note that it is the NXLog agents in the Log Sources tier depicted above that need to fulfill the NXLog v5 requirement in order to natively handle failover, not the NXLog agents in the Relay Cluster. For NXLog deployments that have not yet been upgraded to v5, see the next diagram.
Configuring NXLog v5 and higher for failover
The following sample configurations are based on the architecture
depicted above. For failover to function as depicted,
each of the NXLog relay nodes should have identical module instances
(input, out, relay, etc.), exception for their ListenAddr directive.
<Output to_relay>
Module om_tcp
OutputType Binary
Host 192.168.1.51:1514
Host 192.168.1.52:1514
Host 192.168.1.53:1514
</Output><Extension _json>
Module xm_json
</Extension>
<Input from_Log_Sources>
Module im_tcp
ListenAddr 0.0.0.0:1514
InputType Binary
</Input>
<Output to_archive>
Module om_tcp
Host archival-fs.example.com:1514
OutputType Binary
</Output>
<Output to_siem>
Module om_tcp
Host siem.example.com:1515
Exec to_json();
</Output>| The configurations for sending events to Amazon S3 and SIEMs like Microsoft Azure Sentinel or Splunk require additional setup that is beyond the scope of this chapter. Should you opt to include them in your HA Centralized Log Collection architecture, please visit their respective integration chapters for details on how to prepare and configure the NXLog Relay Cluster nodes for forwarding events to these third-party log analytics and/or long-term archival solutions: Amazon S3, Microsoft Azure Sentinel, and Splunk. |
Using a third-party solution to provide failover within the NXLog Relay Cluster
For NXLog EE deployments that have not yet been upgraded to v5.0, failover needs to be managed by using a third-party load balancing solution that can be configured to operate in active-passive mode, such as HAProxy or Nginx.
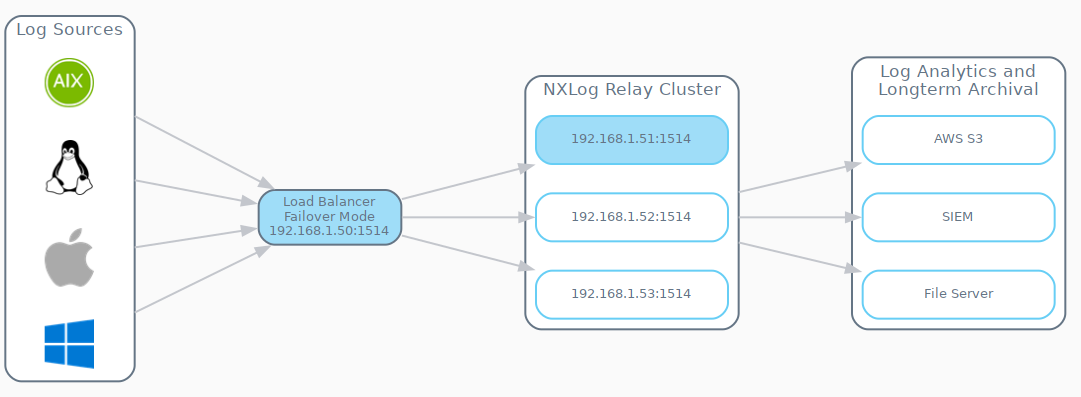
In the following examples, either HAProxy or Nginx can be configured to automatically select the next available NXLog node in the Relay Cluster if the current node becomes unresponsive. Using this approach, all Log Sources will have their output instances configured to send events to the third-party failover provider as depicted in the diagram above.
<Output to_3rd_party_failover>
Module om_tcp
OutputType Binary
Host 192.168.1.50:1514
</Output>Each of the NXLog nodes in the NXLog Relay Cluster are configured to receive events from the third-party failover provider.
<Extension _json>
Module xm_json
</Extension>
<Input from_Log_Sources>
Module im_tcp
ListenAddr 0.0.0.0:1514
InputType Binary
</Input>
<Output to_archive>
Module om_tcp
Host archival-fs.example.com:1514
OutputType Binary
</Output>
<Output to_siem>
Module om_tcp
Host siem.example.com:1515
Exec to_json();
</Output>In this example HAProxy is configured for active-passive mode. The frontend
section defines the listening IP and port (0.0.0.0:1514) of the host where HAProxy is running.
The backend section defines the members of the NXLog cluster, assigns
them labels (nxlog_1, nxlog_2, nxlog_3), along with their listening IP
addresses and ports. The second and third servers (nxlog_2 and nxlog_3) are
flagged with backup to indicate they should remain passive as long as
nxlog_1 is accepting connections and can relay events. The roundrobin
algorithm means each server in the cluster will tested in order, cycling back
to the first server again if the last one in the list fails while serving as
the primary due to previous failures of the ones before it.
frontend tcp_front
bind *:1514
stats uri /haproxy?stats
default_backend tcp_back
backend tcp_back
balance roundrobin
server nxlog_1 192.168.1.51:1514 check
server nxlog_2 192.168.1.52:1514 check backup
server nxlog_3 192.168.1.53:1514 check backupIn this example Nginx is configured for active-passive mode within the
context of a stream block. This is important because HTTP connections are
handled differently than TCP (stream) connections.
Within the server block, the listen directive defines only the port
(effectively 0.0.0.0:1514) that the Nginx host will be accepting connections
on. The proxy_pass directive defines the name of the upstream block,
nxlog_relay_cluster, to which TCP traffic will be directed.
The named (nxlog_relay_cluster) upsteam block defines each server member
of the NXLog cluster by its hostname or IP address and port number. The
second and third servers (192.168.1.52:1514 and 192.168.1.53:1514) are
flagged with backup to indicate they should remain passive as long as
192.168.1.51:1514 is accepting connections and can relay events. Should the
first server fail to accept connections and relay events, each susequent server
in the cluster will tested in order, cycling back to the first server again if
the last one in the list fails while serving as the primary due to previous
failures of the ones before it.
stream {
upstream nxlog_relay_cluster {
server 192.168.1.51:1514;
server 192.168.1.52:1514 backup;
server 192.168.1.53:1514 backup;
}
server {
listen 1514;
proxy_pass nxlog_relay_cluster;
}
}Load balancing
The primary objective of a load balancer is to distribute the workload within a computing environment across a cluster of nodes to mitigate a number of performance issues, such as:
-
Sudden spikes in workload that would otherwise overwhelm a non-distributed computing environment that can easily slow the entire computing environment down to a crawl or even a halt.
-
In an unmanaged cluster, some compute resources will inevitably be working at peak capacity while others sit idle due the random nature of tasks and network traffic. A load balancer can efficiently distribute network traffic and mete out compute tasks across multiple nodes. This optimizes resource utilization and maximizes throughput.
Load balancing can also be used to scale out your application and increase its performance and redundancy.
Architecture
The active-active mode of managing a load balanced cluster of nodes provides the most cost effective use of a cluster and the highest performance attainable. When comparing the architecture depicted in the following diagram with the previous one for Failover, two major differences are apparent:
-
An additional Load Balancing tier has been inserted as a mediator between the Log Sources tier and the NXLog Relay Cluster tier.
-
All nodes in the NXLog Relay Cluster are now active; none are sitting idle waiting for a failure to occur.
For this reason, load balancers are associated first and foremost with performance rather than fault tolerance.
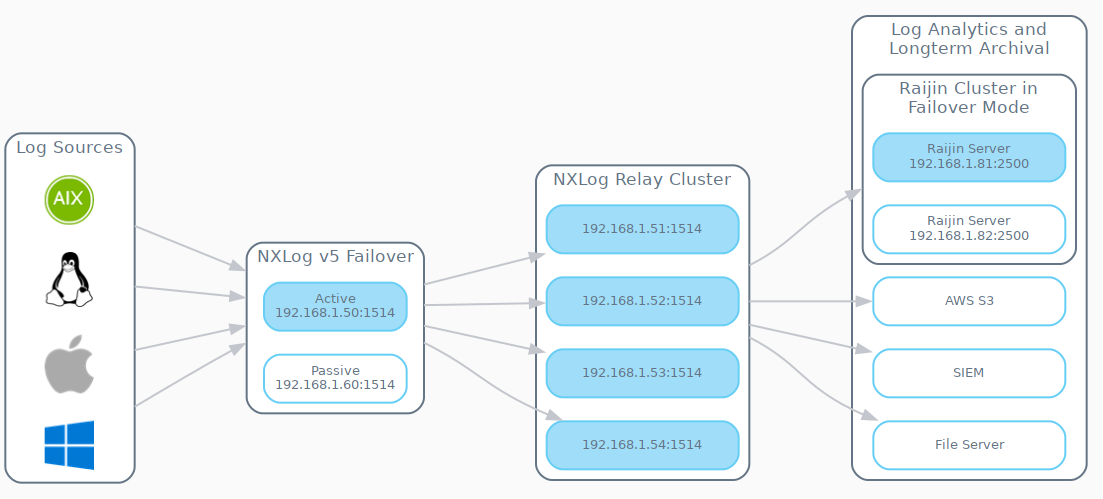
Example implementations of load balancing solutions
In the following examples, the NXLog Relay Cluster is configured for active-active mode. All nodes will be actively used and managed by a load balancer. The dual-node Load Balancer cluster shown above will operate in active-passive (failover) mode by virtue of NXLog Enterprise Edition v5’s built-in externally managed failover capabilities. Each output instance of the productName agents belonging to the Log Sources group in the diagram is configured to send to both load balancers.
| Since neither pre-v5 NXLog Enterprise Edition nor HAProxy nor Nginx (Open Source) ship with built-in failover capabilities, only a single load balancer can be used in standalone mode when configuring pre-v5 Log Sources. |
<Output to_relay>
Module om_tcp
OutputType Binary
# Load Balancer 1 - ACTIVE
Host 192.168.1.50:1514
# Load Balancer 2 - passive
Host 192.168.1.60:1514
</Output>Each of the NXLog nodes in the NXLog Relay Cluster are configured to receive events from the third-party failover provider.
<Extension _json>
Module xm_json
</Extension>
<Input from_Log_Sources>
Module im_tcp
ListenAddr 0.0.0.0:1514
InputType Binary
</Input>
<Output to_archive>
Module om_tcp
Host archival-fs.example.com:1514
OutputType Binary
</Output>
<Output to_siem>
Module om_tcp
Host siem.example.com:1515
Exec to_json();
</Output>In this example HAProxy is configured for active-active mode. The leastconn
load balancing algorithm is recommended for TCP connections that are long-lived.
frontend tcp_front
bind *:1514
default_backend tcp_back
backend tcp_back
balance leastconn
mode tcp
server nxlog_1 192.168.1.51:1514 check
server nxlog_2 192.168.1.52:1514 check
server nxlog_3 192.168.1.53:1514 check
server nxlog_4 192.168.1.54:1514 check
server nxlog_5 192.168.1.55:1514 checkIn this example Nginx is configured for active-active mode. The least_conn
load balancing algorithm is recommended for TCP connections that are long-lived.
stream {
upstream nxlog_relay_cluster {
least_conn;
server 192.168.1.51:1514;
server 192.168.1.52:1514;
server 192.168.1.53:1514;
server 192.168.1.54:1514;
server 192.168.1.55:1514;
}
server {
listen 1514;
proxy_pass nxlog_relay_cluster;
}
}