
Scaling NXLog Manager
Scaling NXLog Manager is required when the performance requirements from the Manager instance are increased, most often because of the elevated number of NXLog agents connected to it. As with almost every IT system, there are two ways that this can be done. Scaling Up or Scaling Out.
This topic is intended to serve as a general guideline for scaling NXLog Manager in order to help avoid common pitfalls.
Scaling Up NXLog Manager
Scaling up, or vertical scaling, means adding more resources to an existing machine to increase its load capacity. In the case of NXLog Manager, this can only be extended to a certain limit. Because of the communication and availability requirements between the agents and NXLog Manager, a single instance of NXLog Manager could only manage approximately 2,000 agents comfortably at most. After that, even adding more resources to the server will not help scaling its capacity any higher.
To efficiently use the resources available for an NXLog Manager instance, the heap size and the open files limit need to be configured according to the needs of the deployment environment.
Once the limit of a single NXLog Manager is reached, horizontal scaling is required.
Scaling Out NXLog Manager
Scaling out, or horizontal scaling, is the technique of increasing the total load capacity of the deployment environment by increasing the number of NXLog Manager instances. By distributing the total load across multiple instances, the individual load each instance has to bear is decreased while overall performance is boosted.
Scaling out an NXLog Manager deployment can become necessary for two reasons. The first scenario has already been mentioned: the need to manage a greater number of clients than can be handled by a single instance. The second is to implement fault tolerance in the deployment environment.
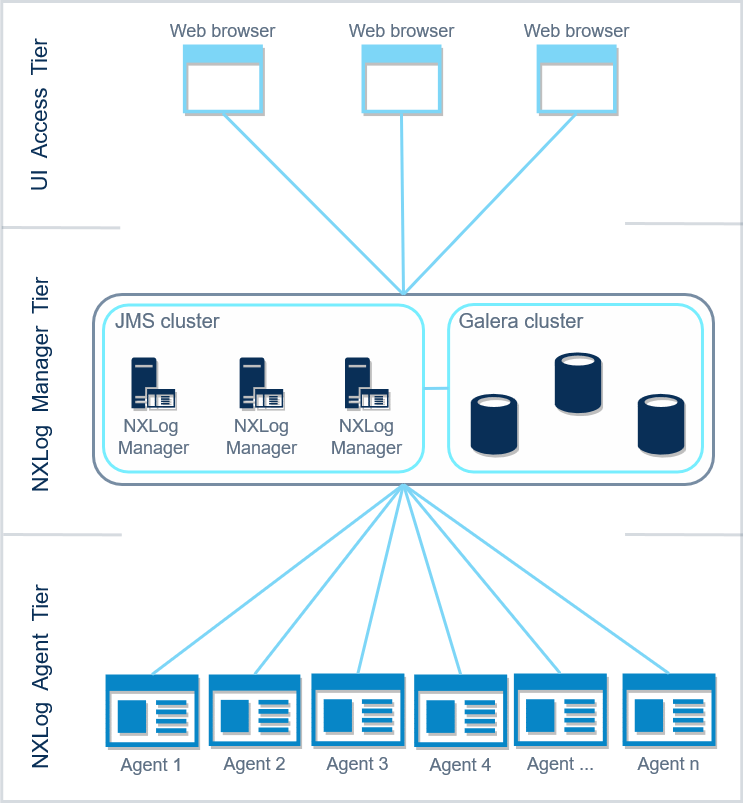
When scaling out, it is best to assess the deployment environment by looking at the different logical areas that it is comprised of. These three logical tiers represent different functional areas of the deployment environment. These are:
-
The UI Access Tier — is where users log in to the NXLog Manager web interface.
-
The NXLog Manager Tier — is where the NXLog Manager instances and the database back end are deployed. The nodes communicate using Java Message Service (JMS) over TCP port 20000. The replicated MySQL database, in this case Galera, serves as a persistent data storage back end for the configuration data.
-
The NXLog Agent Tier — is where the agents are deployed.
| The JMS communication within a cluster works in a mesh topology, each node in the cluster opens a connection to all other nodes. The network configuration of the deployment environment should accommodate this requirement. |
Scaling out NXLog Manager to a cluster can be implemented as seen on the image below.
- NOTE
-
For more information about clustering and running NXLog Manager in distributed mode, see Configuring NXLog Manager for cluster mode.
Port Assignment
Port assignment is a crucial detail when configuring a cluster. The following table lists the values for an NXLog Manager cluster:
| Application | Port number | Notes |
|---|---|---|
JMS |
TCP 20000 |
The port that the JMS cluster is accessed on. |
Galera |
TCP:3306 |
The default port for MySQL client connections. |
TCP/UDP:4567 |
The port reserved for reserved for Galera Cluster replication traffic. |
|
4568 |
Port 4568 is for IST (Internal State Transfer); default is SST (configurable). |
|
4444 |
The port used for all other SST (State Snapshot Transfer). |
|
Agent ⇒ Manager |
4041 |
The port that NXLog Manager listens on for agents. |
UI ⇒ Manager |
9090/9443 |
The ports that the NXLog Manager web interface is accessed on. |
Considerations
The configuration must be set up in a way that agents are evenly distributed among the NXLog Manager nodes. This means that at least as many configuration variants are required as the number of nodes in the cluster. The associations between agents and NXLog Manager nodes must be maintained manually.
Maintaining these associations require careful planning in large environments as the initial connection is coded in the configuration deployed with the agent. Templates can be used to rewrite these, but the initial traffic still flows into a single manager instance. This can be alleviated, by using multiple initial configurations, each variant for a separate group of agents.
If all agents use the same configuration file, they will all be connecting to a single NXLog Manager node, which might overload it while leaving the other manager nodes in the cluster completely idle.
In light of this information, it is recommended that special attention be given the following two considerations when planning a deployment in which NXLog Manager will be scaled out:
- Initial configuration
-
Multiple configurations will be needed to spread the initial load across the NXLog Manager instances. This will allow agents to connect to different instances of NXLog Manager and thus avoid overloading any single NXLog Manager node. Instead, they will connect to their designated manager instance as defined in their respective configuration variants.
- Resilience
-
If an NXLog Manager node goes offline, then all agents connected to it go offline as well. Since configurations can no longer be pushed to the agents formerly managed by the NXLog Manager node that is now offline, they become orphaned.
Load balancing the NXLog Manager Cluster
To help mitigate the potential challenges mentioned above, load balancing can be implemented for the NXLog Manager cluster.
Load balancing the NXLog Manager cluster can be introduced at the UI access tier and at the NXLog Agent Tier (for different purposes of course). The image below displays these two possibilities.
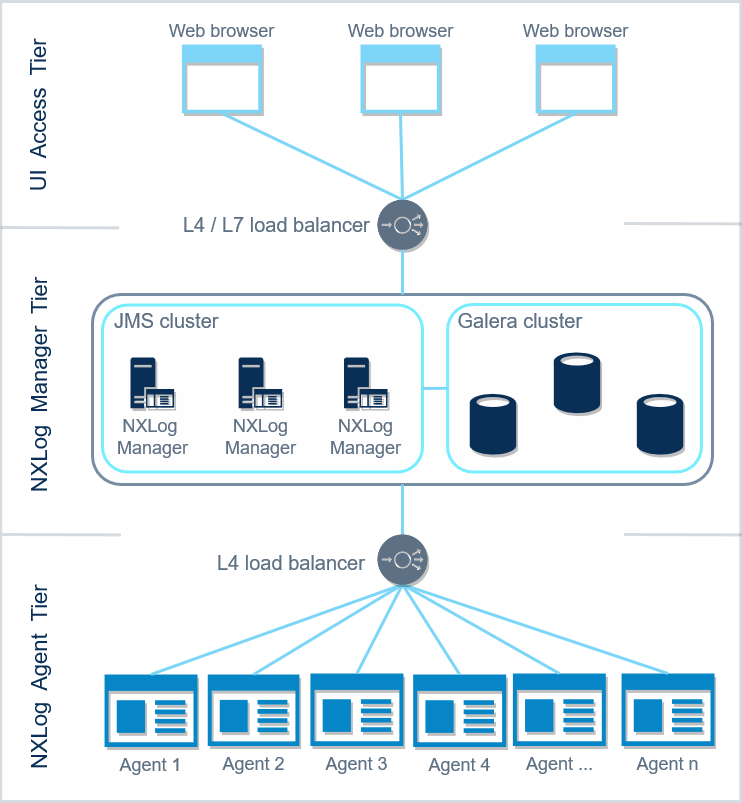
Load Balancing at the Agent Tier
A Layer 4, transport layer, load balancer can be utilized at the Agent Tier to distribute incoming agent communication among the nodes of the NXLog Manager cluster.
The benefit of implementing load balancing at the Agent Tier is that it solves both of the previously mentioned issues, the complexity of the initial configuration and resilience:
-
The initial connection load is automatically distributed with a single configuration file variant since all agents can only connect to the same load balancer.
-
Load balancers can redirect agents to the remaining nodes if an NXLog Manager instance becomes unavailable.
The load balanced environment should fulfill the following requirements:
-
The load balancer should always route agents to the same manager node in its nominal state (failover reshuffles connections).
-
For NXLog Agent to NXLog Manager communications, source-IP-based session persistence should be configured for port 4041.
It is crucial to use consistent, source-IP-based node association on the load balancer to achieve proper persistence, otherwise the agents might reconnect to a different manager node when restarting after a configuration push. In this case, the original manager node waits 30s for the agent to return, then reports it as lost. The agent in question eventually reappears, but it may appear unavailable for a while.
Create a template with the VIP (Virtual IP, the IP address of the load balancer) as the Connect address, and assign it to the agents. Otherwise NXLog Manager overrides the
Connectdirective of the agents with the first configuration push, as a result, agents bypass the load balancer. -
When an NXLog Manager node goes offline, the load balancer should redirect agents to the remaining nodes.
Capacity planning is essential when preparing to deploy NXLog Manager in cluster mode. If all the nodes are operating at full capacity, fully loaded with agents, the entire system may fail when one node goes offline. If resilience is a priority, this is to be avoided.
To prevent such a failure, n+1 sizing should be employed. For example, if three NXLog Manager nodes are deemed sufficient for managing the required number of agents, deploy a four-node cluster instead, to ensure that the remaining cluster nodes are not overwhelmed if one NXLog Manager node goes offline.
|
If an NXLog Manager node goes offline, its orphaned agents will be reassigned. |
|
When agents are behind a NAT or an additional proxy, the load balancer might skew the balance between manager nodes since the NAT device maps agents the same way, thus the load balancer weighs them the same as if they coming from the same IP address. This is because the sessions stick to the source-IP, and some agents may share the same apparent source-IP. |
Planning the Manager Tier Instances
An agent count above 2,000 is likely to require scaling out (cluster mode) for optimal performance.
As an example, to build a deployment that serves 8,000 agents, use 5 (4+1) manager nodes in the NXLog Manager Tier. Such a configuration should manage 8,000 agents easily and contains one additional node for resilience (n+1) with load balancing.
Load Balancing at the UI Access Tier
The traffic from users is rarely heavy enough to justify load balancing for this purpose alone. Also, users connect to any of the nodes directly to access the UI.
Despite being able to access nodes directly, by connecting to the load balancer instead, users can avoid the inconvenience of trying to connect to a NXLog Manager that might be unavailable. For this reason, ensure that the load balancer is configured to remove NXLog Manager nodes from the rotation list as soon as they become unavailable, so that users can always access a working NXLog Manager node as long as there is at least one that is online and functional.
Points to consider when planning to deploy a load balancer in the UI access tier:
-
Session data is not replicated, so sticky sessions must be used on port 9090/9443 of the load balancer.
port 9090 HTTP traffic
port 9443 HTTPS traffic
-
Troubleshooting can get complicated because it is difficult to determine which NXLog Manager node the browser connects to behind the load balancer.
|
Session persistence is a must for the UI access tier. |
NXLog Manager Load Balanced Cluster Management Best Practices
-
Restart each NXLog Manager instance when settings are changed. The UI displays the most recent settings on each node, but the process itself continues to use the old settings until it is restarted.
-
Ensure that key settings (such as heap size, open files limit, etc.) are uniformly managed and remain in sync across the load balanced cluster, otherwise the NXLog Manager cluster is likely to malfunction:
-
For instance, if a node exceeds the open files limit, the disk volume where log messages are stored could fill up.
-
Agents may behave differently depending on which NXLog Manager they are communicating with.
-